Introduzione al compiler design: compilatore per LC-2
Il compilatore è un software che permette di tradurre un codice scritto in HLL (High Level Language) in linguaggio macchina. Consente l’effettiva esecuzione dei programmi da parte del calcolatore. Ma come funziona? Di seguito illustrerò da cosa è composto (per il linguaggio C) e il suo funzionamento, esponendo inoltre un mio progetto di simulatore di assembly LC-2 (Little Computer 2).
Premesse
Ho deciso di approfondire il mondo dei compilatori dopo aver frequentato il corso di programmazione all’università, nell’ambito del quale è stata richiesta la realizzazione di un progetto. Mi ha molto colpito la tematica dei linguaggi formali e ho, dunque, deciso di realizzare un compilatore. L’idea, in realtà, si è consolidata grazie ad un altro corso, “Architettura degli Elaboratori”, nel quale viene approfondita la struttura dei calcolatori e il loro funzionamento. Tale insegnamento utilizza, come esempio di linguaggio assembler e struttura della CPU, l’architettura LC-2: tuttavia, l’ambiente di sviluppo utilizzato nell’ambito del laboratorio consiste in un software di simulazione disponibile esclusivamente su Windows. Da qui, l’idea di sviluppare un compilatore per LC-2 per piattaforme Linux e MacOS.
Ringrazio il Prof. Marco Anisetti per avermi fornito materiale aggiuntivo al corso relativo a questa tematica: alcune informazioni e immagini sono ricavate da tale materiale.
I Traduttori
La fase di traduzione di un linguaggio di alto livello ad un codice comprensibile per un calcolatore (linguaggio macchina) viene eseguita da un traduttore di linguaggio. Esistono due tipi di traduttori:
- il Compilatore
- l’Interprete
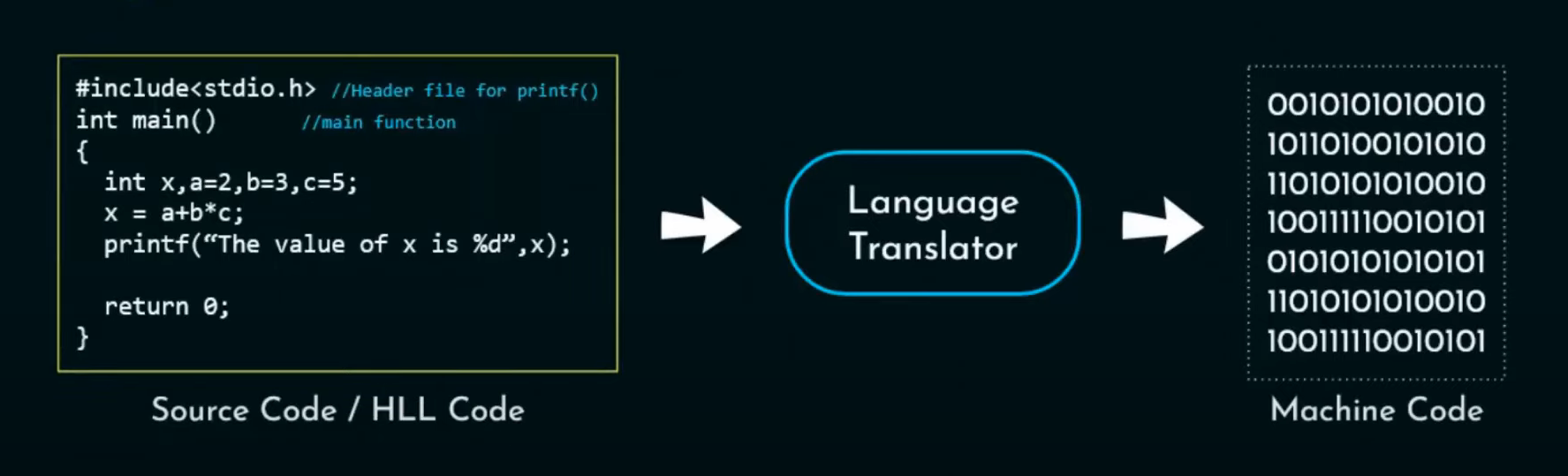
Il compilatore
Programma che traduce un programma scritto in un linguaggio ad alto livello in un programma equivalente in linguaggio macchina (verrà descritto nel dettaglio in seguito). Il linguaggio di programmazione C è un esempio di linguaggio compilato.
Interprete
Programma che simula l’esecuzione del codice riga per riga, sfruttando direttamente il codice sorgente. Ciò avviene in tre passaggi, alcuni dei quali in comune con un compilatore:
- verifica della correttezza sintattica
- traduzione
- esecuzione del codice tradotto
Un esempio di HLL interpretato e non compilato è Python, linguaggio di scripting molto popolare ai giorni nostri, data la sua versatilità d’applicazione in molti campi dell’informatica e della scienza.
Sistema di processing del linguaggio
La fase di traduzione, per il compilatore, si suddivide in 4 parti:
- Preprocessore
- Compilatore
- Assemblatore
- Loader/Linker
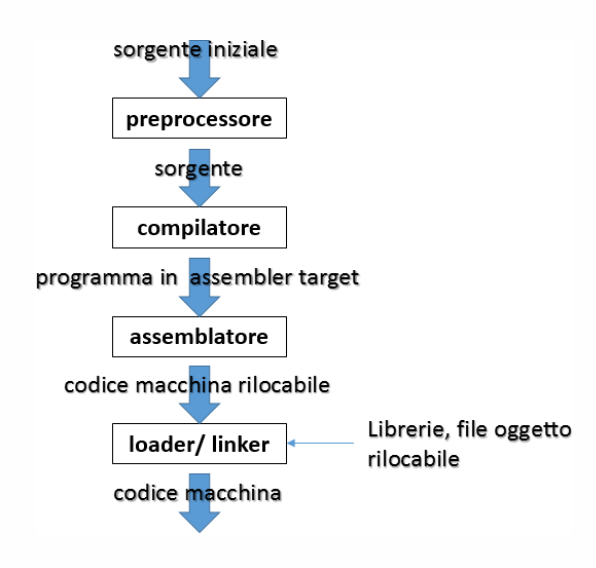
Prima di compilare il codice, viene eseguita una fase di precompilazione: vengono soddisfatte tutte le direttive del preprocessore esplicitate nel source code, come l’inclusione di file esterni, la processazione delle macro e la rimozione dei commenti (per queste operazioni viene adoperato un analizzatore lessicale). Il risultato di questa fase consiste in un codice HLL puro.
Avviene poi la compilazione: il sorgente viene tradotto in codice macchina specifico per una determinata architettura hardware (chiamato “oggetto”, file con estensione .obj), controllando eventuali errori rispetto alla grammatica del linguaggio in questione. Successivamente, l’assembler genera il codice macchina rilocabile: ovvero, codice non dipendente da indirizzi statici di memoria. Viene poi assemblato con altre funzioni di libreria, o altri programmi, utilizzati dal programma tramite un linker, generando l’eseguibile.
Infine, il programma, per poter essere eseguito, ha necessità di essere caricato in memoria di lavoro: è il loader ad occuparsi di questo processo. Linker e loader generano ciò che viene chiamato “codice macchina assoluto”.
Il compilatore: architettura interna
Ci sono due fasi fondamentali nella compilazione: analisi e sintesi.
Durante la fase di analisi viene eseguita l’analisi lessicale, sintattica e semantica; nella fase di sintesi avviene la generazione del codice intermedio, l’ottimizzazione del codice e, infine, la generazione del codice macchina. Le varie fasi verranno analizzate nel dettaglio in seguito.

Rappresentazione alternativa
I diversi stadi possono anche essere logicamente raggruppati in maniera più pragmatica, ovvero, front-end e back-end: questi suddividono le fasi slegate dall’architettura del calcolatore di destinazione (front-end) da quelle che eseguono operazioni specifiche della macchina target (back-end). Ciò permette il riutilizzo della medesima parte di front-end con back-end differenti (cross compilazione).

Struttura interna del compilatore
Il compilatore è composto da:
- Analisi Lessicale
- Analisi Sintattica
- Analisi Semantica
- Generazione del Codice Intermedio
- Ottimizzazione del Codice
- Generazione del Codice Macchina
Spiegherò nel dettaglio le fasi front-end, descrivendo in modo pratico come le ho realizzate nel mio progetto.
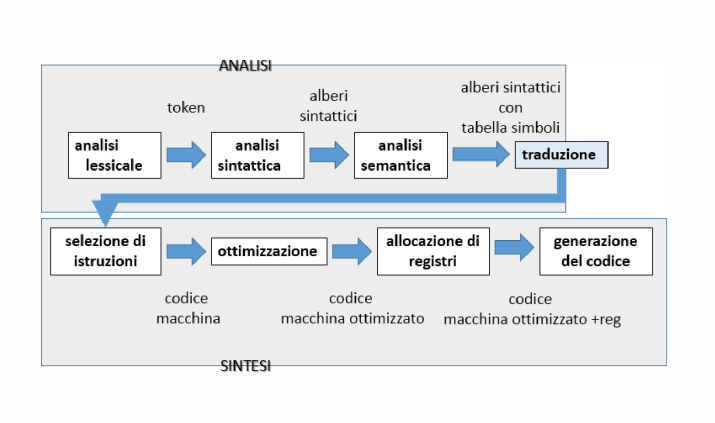
Symbol Table e Error Handler
All’interno del compilatore abbiamo anche altri due fondamentali componenti: la tabella dei simboli (Symbol Table) e l’Error Handler.
La Symbol Table serve ad immagazzinare le informazioni raccolte durante la fase di analisi, per essere poi utilizzate nella fase di sintesi. L’Error Handler gestisce eventuali errori durante tutte le fasi.
Simulatore Assembly LC-2
Essendo un simulatore di architettura, la parte back-end non è stata implementata allo stesso modo di un normale compilatore. Difatti, dopo la fase di analisi semantica, ho emulato l’esecuzione delle singole istruzioni e i loro effetti sui registri del processore e la memoria di lavoro. Vorrei sottolineare inoltre che il linguaggio che sto emulando non è strutturato, quindi la mia implementazione risulterà differente da altri linguaggi strutturati.
Analisi Lessicale
L’analizzatore lessicale: legge Il codice HLL puro carattere per carattere ricevendo in input i lessemi, ovvero i caratteri letti, e produce come output i token, ovvero gli elementi minimi di un linguaggio.
Inserisce le prime entry nella Symbol Table e inoltra i lessemi all’analizzatore della sintassi.
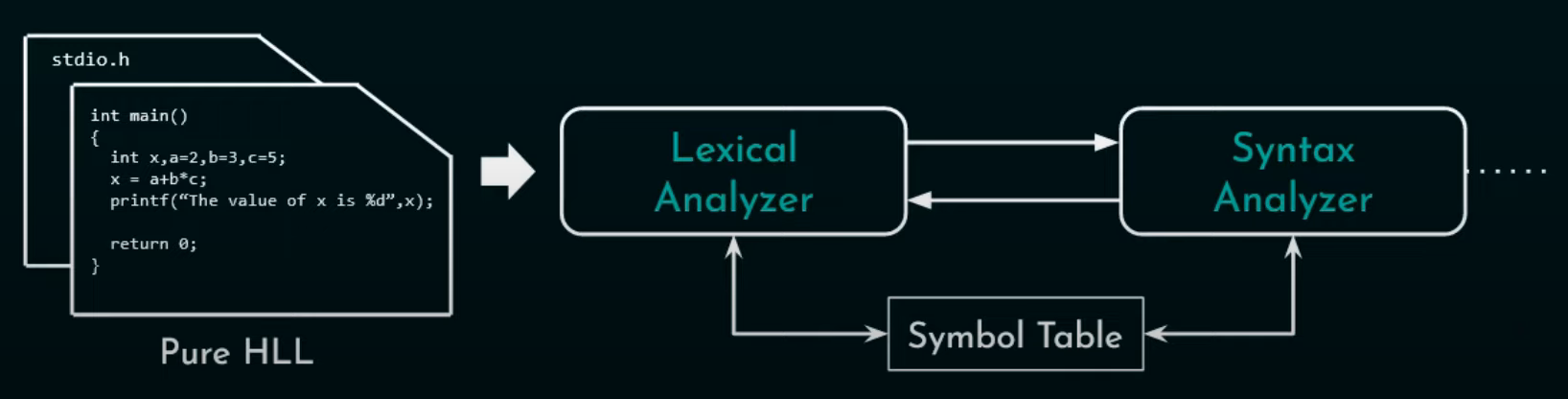
Si può dividere in due fasi:
- fase di Scanning, in cui elementi non-token vengono scartati, come ad esempio i commenti o gli spazi.
- fase di Analyzing, in cui i lessemi vengono associati ai relativi token.
Per la realizzazione dell’analizzatore lessicale vengono impiegate delle macchine a stati finiti. Ad ogni token viene associata una macchina a stati finiti deterministica (MSFD) che permette di generarlo tramite l’analisi dei lessemi.
Lex
Lex è un tool per la generazione di analizzatori lessicali. Tramite la descrizione di specifiche permette di generare un programma scritto in C che ne implementa il funzionamento. Vengono impiegate le espressioni regolari (regex) per l’individuazione dei token. Il linguaggio Lex prevede:
- Parte dichiarativa: con variabili costanti e espressioni regolari.
- Regole di traduzione: che consistono in una espressione regolare ed una azione associata che l’analizzatore deve compiere nel momento che il pattern regolare è riconosciuto.
- Procedure ausiliarie: procedure richieste dalle azioni.
%{
int countline=1;
#include "y.tab.h"
#include "tree.h"
#define TABLE strcpy(yylval.nd_obj.name,(yytext));
%}
%option yylineno
%%
//Regex tokens restituiti
(?i:"RET"|"RTI") {TABLE return RETS;}
(?i:"LD"|"LDI"|"LEA"|"ST"|"STI") {TABLE return LDST;}
(?i:"NOT") {TABLE return NOT;}
(?i:"ADD"|"AND") {TABLE return IMOP;}
(?i:"LDR"|"STR") {TABLE return BSOP;}
(?i:"TRAP") {TABLE return TRAP;}
(?i:"r")[0-7] {TABLE return REGISTER;}
(?i:"br")(?i:"z"|"n"|"p") {TABLE return JUMP;}
(?i:"brn")(?i:"z"|"p") {TABLE return JUMP;}
(?i:"brzp") {TABLE return JUMP;}
(?i:"brnzp") {TABLE return JUMP;}
(?I:"JSR") {TABLE return JSR;}
(?I:"JSRR") {TABLE return JSRR;}
"."(?i:"orig") {TABLE return ORIG;}
"."(?i:"end") {TABLE return END;}
"."(?i:"blkw") {TABLE return BLKW;}
"."(?i:"fill") {TABLE return FILL;}
"."(?i:"stringz") {TABLE return STRINGZ;}
(?i:"b")[0-1]{16} {TABLE return BINARY;}
"x"[0-9a-fA-F][0-9a-fA-F][0-9a-fA-F][0-9a-fA-F] {TABLE return ADDR;}
";".* { ; }
[ \t]* { ; }
[\n] countline++;
"#"[-]?[0-9] {TABLE return NUMBERS;}
"#"[-]?[1][0-5] {TABLE return NUMBERS;}
[-]?[0-9]* {TABLE return NUM;}
[a-zA-Z_][a-zA-Z0-9_]* {TABLE return LABEL;}
["].*["] {TABLE return STR;}
"," {TABLE return COMMA;}
<<EOF>> {TABLE return EOFF;}
. { ; }
%%
Analisi Sintattica
L’analisi sintattica è il processo di costruzione di una frase rispetto ad una determinata grammatica. Utilizza i token individuati dall’analizzatore lessicale per eseguire un controllo sintattico attraverso una Context Free Grammar (CFG). Il risultato di questa fase è un albero sintattico chiamato parse tree. Il programma che svolge questo compito è l’analizzatore della sintassi, anche chiamato parser.
Grammatica di un linguaggio
La grammatica è un’importante sottoclasse dei sistemi generativi, ovvero algoritmi per definire l’appartenenza di una parola ad un linguaggio. Consiste nell’insieme delle regole sintattiche di un linguaggio ed è descritta da una quartupla G = (N, Σ, R, S):
- N insieme dei simboli non terminali, o metasimboli, cioè che non possono comparire negli enunciati del linguaggio
- Σ alfabeto del linguaggio costituito da simboli terminali.
- R insieme finito delle regole di produzione.
- S simbolo non terminale speciale, S ∈ N ed è il punto di partenza che denota un enunciato valido.
Tecniche di generazione del parse tree
In relazione a come viene creato il parse tree,ci sono differenti tecniche, che possono essere divise in due gruppi:
Top-Down Parsing
Analisi sintattica discendente, viene anche definita “predittiva”, dato che la costruzione del parse tree inizia dalla radice e procede verso le foglie.
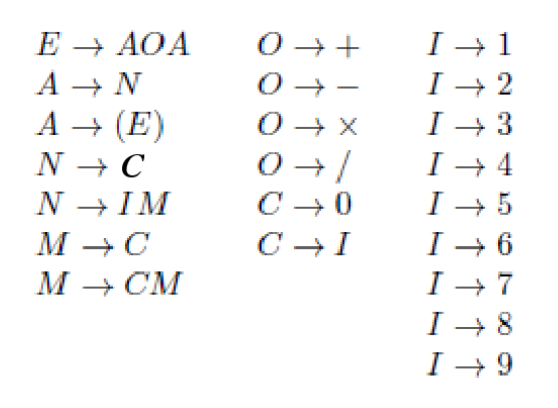

Un problema che può accedere in questi tipi di analisi sintattica è di dover tornare su una decisione presa perchè non porta al risultato, questo fenomeno è chiamato backtracking.
backtracking: la tecnica che prevede di enumerare tutte le soluzioni possibili in ricerca di quella che soddisfa i vincoli.
Esempi di Parser che cercano di evitare il backtracking sono: Predictive Parsers e Recursive Descent Parsers.
Bottom-Up Parsing
Analisi sintattica ascendente, viene anche definita “shift-reduce parsing” dato che la costruzione del parse tree inizia dalle foglie e procede verso la radice.
Shift-reduce parsing
La costruzione del parse tree inizia dalle foglie e procede verso la radice, si parte dalla stringa target e si procede a ritroso per riduzioni verso il simbolo iniziale. Ad ogni riduzione una particolare sottostringa che fa match con la parte destra di una produzione è rimpiazzata dal simbolo sinistro della produzione. L’algoritmo di parsing più famoso di questa categoria è l’LR (left to right scanning of the input, rightmost reduction).
Yacc
Yacc è un programma che permette di generare un parser in C tramite delle regole di derivazione descritte nel suo linguaggio. Appartiene alla categoria LR, più nello specifico è un parser LALR. La notazione utilizzata per le regole di produzione, ovvero le regole della grammatica, è simile alla Backus-Naur form. Inoltre riceve come input i lessemi verificati da Lex.
//struttura file yacc
{declarations}
%%
{rules}
%%
{subroutines}
Di seguito le regole di produzione del mio progetto:
%{
#include <stdio.h>
#include <stdlib.h>
#include "tree.h"
extern int yylex();
extern struct node *head;
extern int yywrap();
extern void add(),yyerror();
int countn=1,count=0,last=0,errors=0;
%}
%union {
struct var_name {
char name[100];
struct node* nd;
} nd_obj;
}
%token <nd_obj> REGISTER RETS LDST EOFF NOT LABEL NUMBERS ORIG COMMENT JUMP COMMA ADDR END BLKW STRINGZ BINARY NUM FILL STR JSR JSRR IMOP BSOP TRAP
%type <nd_obj> program orig lines end endb code ldst ldstb imop imopb bsop ret jump jumpb directive dirb jsr not trap codeb
%start program
%%
program : orig lines end {
$2.nd=mknode($2.nd, $3.nd,"code");
$$.nd=mknode($1.nd, $2.nd,"program");
head = $$.nd;
printf("Analysis completed...\n");
last=1;
}
;
end : endb EOFF { $$.nd = mknode($1.nd, NULL, "end"); }
;
endb : END {
add('D');
$$.nd = mknode(NULL, NULL, "endchar");
}
;
orig : ORIG {add('D');} ADDR {add('V');countn++;
$$.nd=mknode(NULL, NULL, "orig");
}
;
lines : code {countn++; $1.nd=mknode($1.nd, NULL, "line"); }
| lines code {countn++; $$.nd=mknode($1.nd,$2.nd,"lines");}
;
code : ldst {$$.nd=mknode(NULL,$1.nd,"ldst");}
| imop {$$.nd=mknode(NULL,$1.nd,"imop");}
| bsop {$$.nd=mknode(NULL,$1.nd,"bsop");}
| ret {$$.nd=mknode(NULL,$1.nd,"ret");}
| jump {$$.nd=mknode(NULL,$1.nd,"jump");}
| directive {$$.nd=mknode(NULL,$1.nd,"directive");}
| jsr {$$.nd=mknode(NULL,$1.nd,"jsr");}
| not {$$.nd=mknode(NULL,$1.nd,"not");}
| trap {$$.nd=mknode(NULL,$1.nd,"trap");}
| codeb ldst {$$.nd=mknode(NULL,$2.nd,"c-ldst");}
| codeb imop {$$.nd=mknode($1.nd,$2.nd,"c-imop");}
| codeb bsop {$$.nd=mknode($1.nd,$2.nd,"c-bsop");}
| codeb ret {$$.nd=mknode($1.nd,$2.nd,"c-ret");}
| codeb jump {$$.nd=mknode($1.nd,$2.nd,"c-jump");}
| codeb directive {$$.nd=mknode($1.nd,$2.nd,"c-directive");}
| codeb jsr {$$.nd=mknode($1.nd,$2.nd,"c-jsr");}
| codeb not {$$.nd=mknode($1.nd,$2.nd,"c-not");}
| codeb trap {$$.nd=mknode($1.nd,$2.nd,"c-trap");}
;
codeb : LABEL {add('L'); $$.nd=mknode(NULL,NULL,"label");}
;
imop : imopb COMMA REGISTER {
add('R');
$2.nd=mknode(NULL,NULL,"operands");
$$.nd=mknode($1.nd,$2.nd,"op");
}
| imopb COMMA NUMBERS {
add('V');
$2.nd=mknode(NULL,NULL,"operands");
$$.nd=mknode($1.nd,$2.nd,"op");
}
| imopb COMMA BINARY {
add('V');
$2.nd=mknode(NULL,NULL,"operands");
$$.nd=mknode($1.nd,$2.nd,"op");
}
| imopb COMMA ADDR {
add('V');
$2.nd=mknode(NULL,NULL,"operands");
$$.nd=mknode($1.nd,$2.nd,"op");
}
;
imopb : IMOP { add('O'); } REGISTER { add('R'); } COMMA REGISTER {
add('R');
$$.nd=mknode(NULL,NULL,"op");
}
;
bsop : BSOP {add('O');} REGISTER {add('R');} COMMA REGISTER {add('R');} COMMA NUMBERS {
add('V');
$$.nd=mknode(NULL,NULL,"op");
}
;
ldst : ldstb COMMA ADDR {
add('V');
$2.nd=mknode(NULL,NULL,"operands");
$$.nd=mknode($1.nd,$2.nd,"op");
}
| ldstb COMMA LABEL {
add('L');
$2.nd=mknode(NULL,NULL,"operands");
$$.nd=mknode($1.nd,$2.nd,"op");
}
;
ldstb : LDST {add('O');} REGISTER {add('R'); $$.nd=mknode(NULL,NULL,"op");}
;
not : NOT {add('O');} REGISTER {add('R');} COMMA REGISTER {
add('R');
$$.nd=mknode(NULL,NULL,"op");
}
;
jump : jumpb ADDR {add('V'); $$.nd=mknode($1.nd,NULL,"op");}
| jumpb LABEL {add('L'); $$.nd=mknode($1.nd,NULL,"op");}
;
jumpb : JUMP {add('J'); $$.nd = mknode(NULL, NULL, $1.name);}
;
directive : dirb ADDR {add('V'); $$.nd=mknode($1.nd,NULL,"op");}
| dirb NUM {add('V'); $$.nd=mknode($1.nd,NULL,"op");if(atoi($2.name)>32767){yyerror("Constraints error");}}
| dirb BINARY {add('V'); $$.nd=mknode($1.nd,NULL,"op"); int i;for(i=0;$2.name[i]!='\0';i++);if(i!=17){yyerror("Syntax error");}}
| dirb LABEL {add('L'); $$.nd=mknode($1.nd,NULL,"op");}
| BLKW {add('D');} NUM {add('V'); $$.nd=mknode(NULL,NULL,"op");}
| STRINGZ {add('D');} STR {add('S'); $$.nd=mknode(NULL,NULL,"op");}
| endb {$$.nd=mknode($1.nd,NULL,"op");}
;
dirb : FILL {add('D'); $$.nd = mknode(NULL, NULL, "fill");}
;
trap : TRAP {add('O');} ADDR {add('V'); $$.nd = mknode(NULL, NULL, "trap");}
;
ret : RETS {add('O'); $$.nd = mknode(NULL, NULL, $1.name);}
;
jsr : JSR {add('O');} LABEL {add('L'); $$.nd = mknode(NULL, NULL, "jsr");}
| JSRR {add('O');} REGISTER {add('R');} COMMA ADDR {add('V'); $$.nd = mknode(NULL, NULL, $1.name);}
;
%%
void yyerror(const char* msg) {
if(!last){
fprintf(stderr, "%s at line %d code line %d\n\"%s\" \n", msg,countline,countn,yytext);
last=0,errors=1;
}
}
Oltre che alla generazione del parse tree, gestisco gli errori tramite la funzione yyerror, chiamata automaticamente dal parser in caso di errori di sintassi. Popolo inoltre la Symbol Table.
Analisi Semantica
Si occupa di controllare il significato delle istruzioni presenti nel codice di input. Alcuni esempi, nel linguaggio C, sono: check di variabili non dichiarate, type checking e controllo dei limiti degli array. L’analisi semantica integra l’analisi sintattica o traduce alberi sintattici in strutture utili alle elaborazioni successive, sfrutta le informazioni presenti nella tabella dei simboli e i relativi attributi.
Alcuni esempi di controlli semantici presenti nel mio progetto:
directive : dirb ADDR {add('V'); $$.nd=mknode($1.nd,NULL,"op");}
//semantic check
| dirb NUM {
add('V');
$$.nd=mknode($1.nd,NULL,"op");
if(atoi($2.name)>32767){
yyerror("Semantic error");
}
}
//semantic check
| dirb BINARY {
add('V');
$$.nd=mknode($1.nd,NULL,"op");
int i;
for(i=0;$2.name[i]!='\0';i++);
if(i!=17){
yyerror("Semantic error");
}
}
| dirb LABEL {add('L'); $$.nd=mknode($1.nd,NULL,"op");}
| BLKW {add('D');} NUM {add('V'); $$.nd=mknode(NULL,NULL,"op");}
| STRINGZ {add('D');} STR {add('S'); $$.nd=mknode(NULL,NULL,"op");}
| endb {$$.nd=mknode($1.nd,NULL,"op");}
;
Generazione del codice intermedio
Il Parse Tree verificato semanticamente viene dato in input al generatore di codice intermedio, che produrrà come output il codice intermedio. Un esempio di rappresentazione intermedia è: “Three-address code” (TAC o 3AC), un codice di basso livello simile al linguaggio macchina. Ogni istruzione nella forma 3AC può essere descritta dalla quadrupla (operatore, operando1, operando2, risultato), nella forma y = x op z.
La simulazione
Siccome il mio progetto non è di un compilatore bensì di un simulatore, eseguo una fase di simulazione in cui viene emulato il funzionamento dell’architettura LC-2, su cui viene eseguito il programma (il codice di questa parte si trova nel file exec.c). La symbol table viene modificata per addattarsi ad una generazione del codice intermedio con un ordinamento degli elementi e la duplicazione dei lessemi per avere il codice completo.
Symbol Table finale
Di seguito riporto un esempio di Symbol Table del mio programma (modificata per essere ordinata e con elementi duplicati, la vera symbol table non dovrebbe contenere due lessemi uguali) a seguito del processo di Analisi con tutte le informazioni necessarie alle prossime fasi.
SYMBOL TABLE
VALUE TOKEN_TYPE LINE NUMBER
_________________________________________________________________________
.ORIG directive 1
X3000 value 1
LEA opcode 2
R0 register 2
ARRAY label 2
AND opcode 3
R2 register 3
R2 register 3
#0 value 3
CICLO label 4
LDR opcode 4
R1 register 4
R0 register 4
#0 value 4
BRZ jump 5
FINE label 5
ADD opcode 6
R2 register 6
R1 register 6
R2 register 6
ADD opcode 7
R0 register 7
R0 register 7
#1 value 7
BRNZP jump 8
CICLO label 8
FINE label 9
ST opcode 9
R2 register 9
RESULT label 9
STOQUI label 10
BRNZP jump 10
STOQUI label 10
ARRAY label 11
.FILL directive 11
15 value 11
.FILL directive 12
-27 value 12
.FILL directive 13
13 value 13
.FILL directive 14
15 value 14
.FILL directive 15
0 value 15
RESULT label 16
.BLKW directive 16
1 value 16
.END directive 17
Conclusioni
In questo paper è stato discusso lo scopo, il funzionamento e le fasi di un traduttore di linguaggio: il compilatore. Sono state approfondite le fasi principali della compilazione, mostrando il mio progetto di simulatore di Assembly LC2.
Informazioni utili
- Serie su YouTube Compiler Design
- Simulatore di Assembly LC-2
- Lex e Yacc
- LC-2